
쓰레드 풀을 사용하는 이유
쓰레드는 무한히 생성할 수 있다. 물론, 이런 쓰레드를 여러개 사용해 동시에 병렬 처리를 하면 빠르게 연산처리를 할 수 있다. 하지만 하드웨어는 물리적으로 병렬처리하는 데에 한계가 있다. 결국 이 한계가 있는 리소스를 동시에 사용하기 위해서 쓰레드간 리소스를 서로 차지해가며 각자 본인의 일을 처리한다. 즉, 그에 따른 쓰레드 생성과 스케줄링으로 인해 CPU가 바빠져 메모리 사용량이 늘어난다.
이러한 쓰레드 폭증을 막기 위해서 쓰레드 풀을 사용해야 한다.
쓰레드 풀이란?
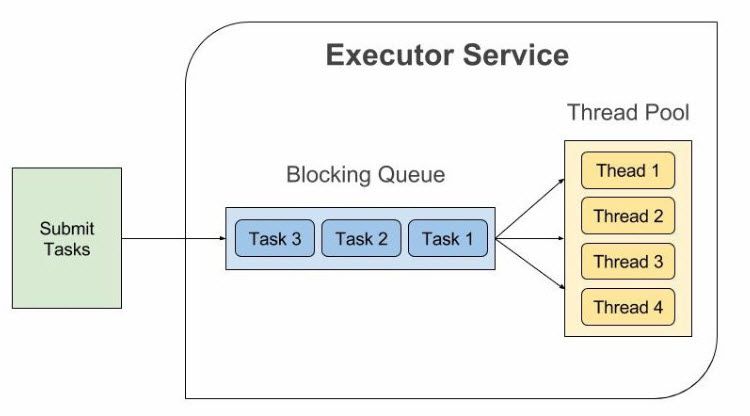
쓰레드 풀은 작업 처리에 사용되는 쓰레드를 제한된 갯수만큼 정해놓고, 작업 큐(Queue)에 들어오는 작업들을 하나씩 쓰레드가 맡아서 처리하도록 한다.
아무리 작업 처리 요청이 많아도 쓰레드의 전체 개수가 늘어나지 않기 때문에 어플리케이션 성능이 급격하게 저하되지 않는다.
쓰레드 풀의 사용 장점 :
- 쓰레드를 생성/수거하는데 비용이 들지 않아 전체적인 퍼포먼스 저하를 방지한다.
- 다수의 사용자 요청을 처리할 수 있다.
- 쓰레드를 미리 생성하여 대기하게 할 수 있다.(리소스의 생성/소멸 비용을 절감 할 수 있다.)
단점 :
- 쓰레드를 너무 많이 생성하도록 설정했을 경우, 메모리 낭비를 야기할 수 있다.
- 노는 쓰레드가 발생할 수 있다.
forkJoinPool을 이용해 해당 문제를 해결
쓰레드 풀 생성
쓰레드 풀은 java.util.concurrent패키지 내 Executors클래스, ExecutorService인터페이스를 이용하여 Thread Pool을 만들 수 있다.
| 메소드명 | 초기 스레드 수 | 코어 스레드 수 | 최대 스레드 수 | 특이사항 |
|---|---|---|---|---|
| newSingleThreadExecutor() | 0 | 1 | 1 | 단일 Worker Thread |
| newCachedThreadPool() | 0 | 0 | Integer.MAX_VALUE | 일 없이 60초동안 아무일을 하지 않으면 쓰레드를 종료시키고 쓰레드 풀에서 제거한다. 이전에 생성된 thread가 존재하면 재사용한다. |
| newFixedThreadPool(int num) | 0 | num | num | 일 없이 놀고 있어도 쓰레드를 제거하지 않는다 |
| newScheduledThreadPool(int num) | - | - | - | 일정 시간 뒤 실행하는 작업이나, 주기적으로 실행하는 작업시 주로 쓰인다 |
| newWorkStealingPool | ? | ? | ? | 자바 8에서 새로 생긴 풀이다. 지정된 parallelism을 지원할만큼 충분한 쓰레드를 유지하고, 여러 Queue를 사용해 경합을 줄인다. 또한, Thread를 동적으로 늘리고 줄이며 작업이 실행되는 순서가 보장되지 않는다. |
- 초기 쓰레드 수 : 기본적으로 생성되어야 하는 쓰레드 수
- 코어 쓰레드 수 : 쓰레드가 증가한 후, 사용되지 않은 쓰레드를 쓰레드 풀에서 제거할 떄 최소한으로 유지해야 할 수
- 최대 쓰레드 수 : 쓰레드 풀에서 관리하는 최대 쓰레드 수
쓰레드 풀 종료
쓰레드 풀은 데몬 쓰레드(=사용자 쓰레드가 종료되면 무조건 종료처리)가 아니기 때문에, main()가 종료되어도 계속 실행 상태로 남아있다. 애플리케이션을 종료하기 위해서, 스레드풀을 종료시켜 스레드들이 종료상태가 되도록 처리 해주어야 한다.
| 리턴타입 | 메소드명(매개변수) | 설명 |
|---|---|---|
| void | shutdown() | 작업큐에 남아있는 작업까지 모두 마무리 한 후 종료한다.(오버헤드를 줄이기 위해 많이 사용됨). 더이상 쓰레드 풀에 작업을 추가하지 못한다 |
| List | shutdownNow() | 작업 중인 쓰레드를 interrupt하여 작업 중지를 시도하고, 쓰레드 풀을 종료시킴 |
| boolean | awaitTermination(long timeout, TimeUnit unit) | shutdown() 호출 후, 모든 작업 처리를 timeout 시간 내 처리하면 true, 아니면 interrupt() 하고 false 리턴한다 |
작업 생성
자, 이제 쓰레드 풀에서 쓰레드를 할당받아 실행할 작업을 생성해본다. 작업 생성시 Runnable 인터페이스 혹은 Callable 인터페이스를 구현한 객체로 실행한다.
Runnable을 통한 구현 객체
Runnable task = new Runnable() {
@Override
public void run() {
//작업 내용을 여기에 적어둔다.
}
}
Callable을 통한 구현 객체
Callable<T> callable = new Callable<T>() {
@Override
public T call() throws Exception {
//작업 내용을 여기에 적어둔다.
return null;
}
}
코드를 통해서 확인 할 수 있듯이, Runnable은 리턴 값이 없고, Callable은 generic을 사용해 어떤 타입이던 리턴 값 을 반환한다.
작업 처리 요청
Runnable과 Callable을 이용해 작업을 생성했으면, 그 뒤에는 쓰레드 풀에 해당 작업을 처리하도록 요청해야 한다.
ExecutorService의 작업 큐에 Runnable 또는 Callable 객체를 넣어야 한다. 객체를 넣기 위해 아래 두가지 방법을 제공한다.
execute()- 작업 처리 결과를 반환하지 않는다.
- 작업 처리 도중 예외가 발생하면 쓰레드가 종료되고, 해당 쓰레드는 쓰레드 풀에서 제거된다.
- 다른 작업을 처리하기 위해 새로운 쓰레드를 생성한다.
Runnable을 작업 큐에 저장한다.
submit()- 작업 처리 결과를 반환한다(
Future반환). - 작업 처리 도중 예외가 발생하더라도 쓰레드는 종료되지 않고 다음 작업을 위해 재사용된다
- 쓰레드의 생성 오버헤드를 방지하기 위해 이 함수를 가급적 사용한다.
Runnable혹은Callable을 작업 큐에 저장한다.
- 작업 처리 결과를 반환한다(
예제 코드 :
package e.thread.sync;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
public class ExecutorSample {
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
for(int i=0; i<10; i++){
Runnable runnable = new Runnable() {
@Override
public void run() {
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executorService;
int poolSize = threadPoolExecutor.getPoolSize();
String threadName = Thread.currentThread().getName();
System.out.println("[총 스레드 개수 : " + poolSize + "] 작업 스레드 이름 : " + threadName);
// Exception
int value = Integer.parseInt("Integer 넣어야 하는데 String을 넣으면");
}
};
executorService.execute(runnable); //submit()메소드로 변환 할 수 있다(쓰레드 종료되지 않음)
Thread.sleep(100);
}
executorService.shutdown();
}
}
블로킹 방식의 작업 완료 통보
ExecutorService의 submit()메소드는 파라미터로 넘겨준 Runnable 혹은 Callable 작업을 쓰레드 풀의 작업 큐에 저장하고, 즉시 Future 객체를 반환한다.
Future객체는 작업 결과가 아니라, 작업이 완료될 때까지 기다렸다가 최종 결과를 얻는데 사용한다. 그래서 Future는 지연 완료(pending Completion)객체라고 한다.
Future의 get()메소드 호출 시, 쓰레드가 작업을 완료할 때 까지 블로킹 되었다가 작업을 완료하면 처리 결과를 리턴한다. 이러한 방식을 블로킹을 사용하는 작업 완료 통보 방식이라고 한다.
주의 : Future의 get()메소드는 쓰레드가 작업이 완료될 때 까지 블로킹되기 때문에 다른 코드를 실행 할 수 없다. 그래서 get()메소드를 호출하는 쓰레드는 새로운 쓰레드 혹은 쓰레드 풀의 또 다른 쓰레드가 되어야 한다.
submit()메소드의 파라미터에 따른 ` future.get()`반환 리턴 타입
submit(Runnable task): null 반환submit(Runnable task, Integer result): int 타입 값 반환- ` future.get(Callable
task)` : String 타입 값 반환 쓰레드가 작업 처리 도중 인터럽트되면 `InterruptedException`을 발생시키고, 작업 처리 도중 예외 발생시 `ExceutionException`을 발생시킨다. 그래서 아래와 같이 예외처리를 진행해주어야 한다.
try{
future.get();
} catch(InterruptedException e){
} catch(ExecutionException e){
}
리턴 값이 없는 작업 완료 통보
리턴 값이 없을 경우, Runnable객체로 생성해 submit(Runnable task)를 실행한다. 결과 값이 없어도 Future 객체를 리턴하는데, 이는 쓰레드가 작업 처리를 정상적으로 완료했는지, 예외가 발생했는지 확인하기 위해서다.
리턴 값이 있는 작업 완료 통보.
쓰레드가 작업을 완료 한 후, 처리 결과를 얻어야 한다면 작업 객체를 Callable로 생성한다.
submit()메소드는 작업 큐에 Callable 객체를 저장하고 즉시 Future를 리턴한다.
쓰레드가 Callable 객체의 call()메소드를 모두 실행하고 T 타입의 값을 리턴하면, Future의 get()메소드는 블로킹이 해제되고 T 타입의 값을 리턴한다.
참고 자료 :
